
25+ Patterns for High Performance Software (Part 1)
Batching, compression, streaming, pipelining and other best practices for low latency and high throughput

Say you want to design a performant:
Data pipeline
Video streaming service
Search engine
Embedded database
Sure, inlining your functions, unrolling your loops, tuning your compiler, and increasing your L1 cache hit rate will help. So will perf flamegraphs or Big O notation.
But really, you’ll want system level techniques. Techniques like pre-processing videos to extract thumbnails of each scene (pre-computation). Or writing first to memory, then flushing to disk periodically in your embedded database (buffering).
In the following blog posts, I’ll describe around 25 patterns for low latency, high throughput software. This post goes over the first 10. Many I noticed in my own projects, while others I found by analyzing different open source projects I’ve worked with.
1) Asynchronous processing
Asynchronity reduces latency by reducing the work needed to service a request. How? It defers this work to later in time.
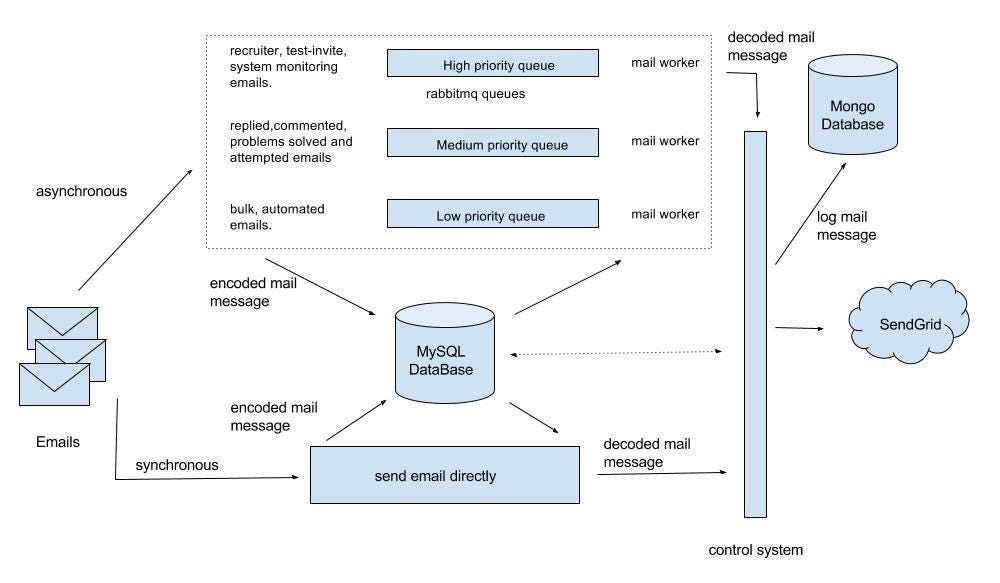
Example: Email delivery. When you request Sendgrid to send transactional email on your behalf, for instance for a password reset email, the request is accepted immediately but emails are sent later on, in the background.

Example: Asynchronous IO. For example, in Node.js, when a I/O operation is initiated, the program doesn’t wait for the I/O operation to complete. Instead, it registers a callback function which is run once the I/O operation completes. The program then continues.
2) Pre-computation
Pre-computation also reduces latency by reducing the work needed to service a request. However, it defers the work to earlier in time.

Example: Twitter timelines. Twitter pre-computes home timelines for each user and stores them (list of post IDs per user) into Redis.
These timelines are computed by merging and ranking posts from accounts the user follows, recommended posts, as well as ads.
(Aside: Derived data platforms like Elephant DB and Venice, designed specifically for pre-computed data, offer an alternative to Redis.)
Example: Cloudflare HTTP request analytics. Cloudflare logs 6M requests per second. It then needs to provide a dashboard to customers showing different statistics about their domains’ traffic.
Cloudflare achieves this by storing logs in Clickhouse and building rollup tables which pre-aggregate statistics like request count per colocation, per HTTP status, by country, by content type, etc.
3) Pooling
Pooling means having a pre-initialized set of objects. Pooling is a form of pre-computation as you don’t need to initialize objects at request time.
Benefits include:
Reduce object creation time
Avoiding the time it takes to create a new object
Reducing resource usage by reusing existing objects
Enforce a maximum number of objects
Example: pooling EC2 instances for EKS clusters. If it’s taking too long to spin up EC2 instances to create a EKS cluster, AWS could maintain a pool of EC2 instances that can be used immediately.
A background job could keep adding new instances to the pool as they are removed.
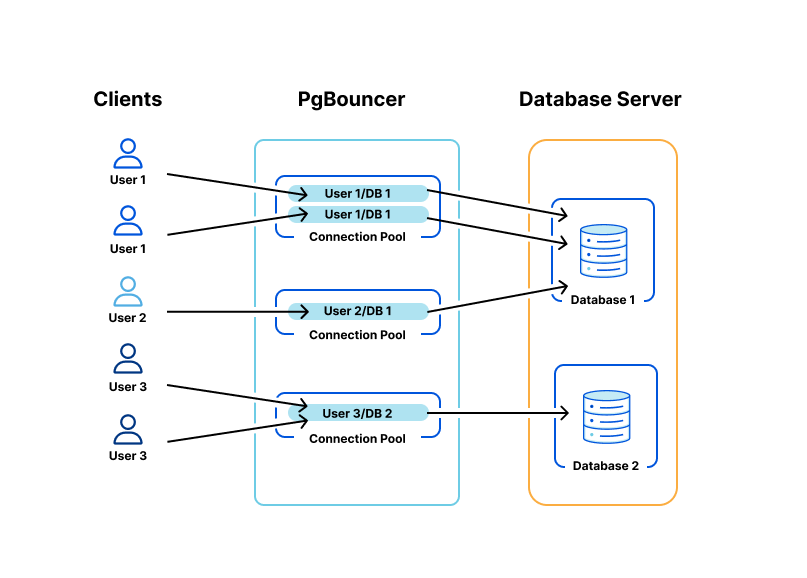
Example: Database connection pooling. Database connections are expensive to create, so you can keep a minimum number of connections in your pool at all times, which you can then reuse between HTTP requests.
Furthermore, you can set a maximum connection pool size to ensure your database is not overloaded.
Example: AWS S3 connection pooling. Internally, AWS SDKs maintain a S3 connection pool, although S3 exposes a (stateless) HTTP API. This way, you can avoid doing a TCP handshake every time you call S3. HTTP libraries should be able to do this for you too using Keep-Alive.
4) Caching
Caching means storing a subset of data in a faster data store. Benefits include:
Lower latency: As you are fetching data from a faster data store, like L1 cache instead of main memory, or main memory instead of disk, or disk instead of a object store
Higher scalability: Caches let you serve repeated requests cheaply rather than having to linearly scale servers to accomodate them.
Caches are smaller than their primary data stores. Caches achieve have a outsized impact because they have high hit rates relative to their size.
How? They exploit spatial or temporal locality: The data to be accessed next is likely near data seen recently on disk, or in time.

Example: Memory hierarchy. Computers can store data L1, L2, L3 caches, RAM, disk, and over the network. L1 is closer (meaning faster to access) than L2 but smaller, L2 is closer but smaller than L3, and so on.
Example: Atlassian Tenant Context Service. Atlassian created a single digit millisecond, multi-region service to provide tenant metadata.
How? Each pod request first hits a local Guava cache, and if needed hits Dynamo DB. Cache hit rate is kept high by refreshing the Guava cache periodically in the background, which reduces P99 latency.
Example: Uber’s geofencing service. Similar to TCS, Uber’s geofencing service serves all requests from in-memory data structures, designed for fast serving. These data structures are periodically and atomically updated by another process in the background.
Example: Spotify on-device caching. Spotify caches songs on users’ devices so they don’t need to be fetched when a user requests them.

Example: Grafana Loki caches. Loki caches raw log data (aka chunks) in Memcached to serve LogQL queries faster. In Loki, the primary store for chunks is a object store like S3.
Loki also caches partial LogQL query results. For instance, if you request all logs for the last one hour, Loki might break that query down into 6 sub-queries, each requesting logs for 10 minutes. Then it’ll look up each of those sub-queries in the query cache.
Example: Dynamo DB DAX. DAX is a managed, in-memory, in-line cache you can add to your Dynamo DB installation. Unlike most caches, you don’t need to maintain DAX’s cache consistency yourself. You can send all requests to DAX, and in the case of a cache miss, DAX will fetch data from Dynamo and update its own data.
5) Batching
Batching means grouping and performing work together so as to make more progress with fewer operations. Batching increases throughput.
Example: Batching writes to Kafka

Kafka producers can batch messages for you. In the sample code below, we publish 100k messages to Kafka.
Our producer will accumulate messages in memory until it has either 5000 bytes in memory (not messages!), or 10 milliseconds has elapsed, then it will publish to the Kafka topic.
At the end, we run producer.flush() to publish any remaining messages in memory and thus gracefully shut down our server.
from confluent_kafka import Producer
# Kafka topic
topic = 'your_kafka_topic'
# Kafka producer configuration
producer_config = {
'bootstrap.servers': 'your_kafka_broker_address',
'client.id': 'batched-producer',
'batch.size': 5000, # Maximum size of a batch (in bytes)
'linger.ms': 10 # Maximum time to wait for more messages (in milliseconds)
}
# Create Kafka producer
producer = Producer(producer_config)
# Generate 100,000 messages
messages = [f'Message{i}' for i in range(1, 100001)]
# Send messages to Kafka
for message in messages:
producer.produce(topic, value=message)
# Wait for any outstanding messages to be delivered and delivery reports received
producer.flush()
# Close the Kafka producer
producer.close()Example: Batching reads in Kafka
You can read multiple messages from a Kafka topic in a consumer at once, by adjusting parameters including poll timeout andmax.poll.records

Example: Batching writes to Clickhouse
Clickhouse recommends bulk loading data in batches of at least 1000 rows and ideally between 10,000 and 100,000.
This is because a excess number of small writes triggers a lot of background merge operations on disk, slowing down your server. Clickhouse can also batch for you, using asynchronous inserts.
6) Buffering
Buffering means storing data in a temporary location.
Data is often buffered in memory, making it faster to access than reading from disk or across the network. Often, you’ll buffer data you don’t need yet, but will need soon.

Example: Buffered IO. Filesystems write data to memory, then flush to disk asynchronously, rather than writing each byte immediately to disk when requested by programs (which would be much slower).
Example: Media streaming. Video and audio streaming services like Spotify and YouTube fetch more data than needed to play the immediate clip, and buffer it in memory.
Example: Message brokers. Message brokers like Kafka ensure no data is lost if a producer is faster than consumers, or if consumers are offline.
Another use case is queue-based load-leveling, where requests are first written to a message broker before being processed. This protects against load spikes, as not all requests are processed right away.
Example: Keyboard input. Operating systems buffer keyboard input in a queue in memory. The OS can then read from the queue at its own pace, meaning input is not lost even if the CPU is busy with other tasks.

Example: Asset preloading in websites. The browser can download images, JS files, etc locally even before you visit the relevant page
7) Compression
Compression reduces the amount of data at rest or in transit by encoding it more efficiently. Benefits include:
Lower storage costs
Reduce memory usage, disk usage, network bandwidth usage
Fewer IO operations needed
Higher cache efficiency
Compression does require additional CPU to compress and de-compress. However, since most programs are IO bound, this is acceptable.
Example: Compression in Clickhouse. You can configure different compression codecs, per-column, in Clickhouse. Options include Delta, DoubleDelta, Gorilla, T64, LZ74, and ZSTD.
This blog post goes over how tuning compression in Clickhouse can speed up queries several times.
8) Data format optimization
Data format optimization means improving how data is encoded and laid out on disk. It can also mean switching file formats.
The better that data access patterns align with which IO operations are fast on modern hardware, the faster reads and writes will be.
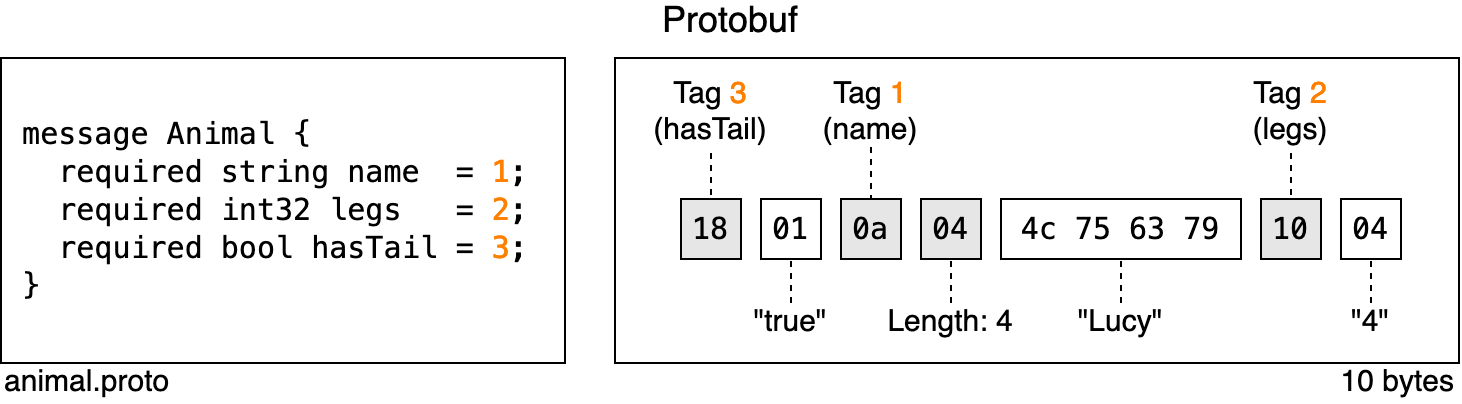
Example: Binary encoding format. Using a binary format like Avro or Protocol Buffers instead of human-readable JSON reduces data size on disk (and thus data size to query).
For instance, while Prometheus metrics are exposed in a textual format, OpenTelemetry metrics are shipped in a binary format.
Example: Row vs column oriented. OLAP databases like Clickhouse store data in a column oriented manner as they optimize for computing aggregations over columns, not retrieving records.
Data lakes often store data in Parquet format for the same reason.

Example: Apache Arrow. Arrow is a common in-memory (columnar) format for different projects like databases and message brokers.
Supporting Arrow in your big data project gives you zero copy reads, drastically cutting IO (de-)serialization time.
You also get for free the library of fast data processing code written for Arrow (using SIMD).
9) Streaming
Streaming means loading or sending only a subset of a dataset at a given time. Benefits include:
Lower memory usage
Lower (first byte) latency

Example: File uploads. Say you are making a file upload service. Instead loading in each uploaded file into memory at once, you can stream each file in chunks and then write each chunk to disk. You can use HTTP Chunked Encoding for this.
This reduces, and bounds, memory usage. Before, to support 100 GB file uploads, you would need 100 GB of memory. Now less memory suffices.

Example: ChatGPT. ChatGPT uses Server-Sent Events to send answer text as it is generated, rather than generating all the text and sending it at once.
10) Pipelining
Pipelining allows multiple steps which depend on each other to execute at once. It is a form of parallelism.
If a process has multiple steps, don’t wait for the prior step to create a full output before proceeding with the next step.
Instead, begin the next step immediately after getting some output from the previous step.

Example: CPU instruction execution. Taking the example above, before pipelining, the CPU executes one instruction every 5 cycles. After pipelining, the CPU can execute one instruction per cycle.

Example: Spark DAG execution. Hadoop writes the results of each intermediate job to disk. It doesn’t support pipelining either: Only after one step is fully completed, and output written out, can the subsequent step begin.
On the other hand, Spark operates on in-memory data (stored in Resilient, Distributed Datasets). As partial output for one step is available, the next step can begin.
Example: Fast TAR extraction. Bash can natively pipeline:
wget -O - https://example.com/demo.tar | tar xvzfThe command above downloads the file, writing bytes incrementally to standard output. As new bytes are downloaded, we tar them.

Databricks then developed fastar. Multiple threads download portions of the file in parallel to a shared in-memory buffer.
Portions of the buffer are then written to standard output and then decompressed.
Finally, multiple threads write the decompressed results to disk in parallel.